5. Discrimination
As was established in the introduction, we can define discrimination at either the group level or the individual level. In the context of this project, before even debating which one of these approaches might be more justifiable, it will be important to examine what data we have available to us. Below is a brief summary of what characteristics would be legal or moral grounds for claiming discrimination and what characteristics are available to us through the data.
What variables are there grounds to use for a discrimination argument?
- Age
- Disability
- Equal Pay/Compensation
- Genetic Information
- Harassment
- National Origin
- Pregnancy
- Race/Color
- Religion
- Retaliation
- Sex
- Sexual Harassment
Characteristics that are protected by being an Equal Housing Lender (which Lending Club is):
- Race
- Color
- Religion
- National origin
- Sex
- Handicap
- Familial status
Other variables research suggests is correlated to socioeconomic status and other important socio-political outcomes:
- Education
- Unemployment
- Poverty
- Income/wealth
What characteristics are available to us?
Through LendingClub, these characteristics might be valuable to investigate at the individual-level:
- Income
- Loan description
- Debt-to-income ratio
- Number of mortgage accounts
- Job description
LendingClub provides the first three digits of each approved applicant’s zip code. This allows us to get a sense of the demographics of an individual’s area from Census data, which we re-aggregated at the three-digit zip level after it was provided to us at the five-digit zip level. Thus, we can examine these Census demographics to get at group-level fairness:
- Race
- % of zip code that is nonwhite
- Education
- % of zip code that holds a Bachelor’s degree
- Family status
- % of zip code that has single parent families
- Gender x age
- % of zip code that is female age 30-39, for instance
- Unemployment rate
- % of zip code that is unemployed
- Workforce
- % of population over 16 years old in the labor force in a zip code
- Household income
- median income in a zip code
Moving forward, our potential options for assessing discrimination are as follows:
| Type | Features |
|---|---|
| Individual-level fairness | Income |
| Group-level fairness | Race, family status, education, unemployment |
For this task, we consider the data available and assert that examining group-level fairness is more justifiable than individual-level fairness.
- More information, i.e., Census data, is available at the group-level
- The data we have at an individual-level that we could use to study discrimination is limited to income, which is not actually a characteristic that can be used to justify individual-level discrimination at this time for this task
- We find the group-level discrimination argument - that giving more loans to people of historically advantaged racial groups, education brackets, family situations, and employment statuses can ingrain pre-existing hierarchies - more compelling than the individual-level one for the task of investing in a large number of loans across the nation
As such, we will focus on the group-level fairness dimension. Specifically, we will examine
- whether Lending Club’s process of approving loan applicants is correlated to zip code and, in turn, whether it is correlated to these four demographic characteristics of a zip code,
- whether our lending strategy that hinges around modeling probability of default to maximize return on investment is discriminatory,
- and whether we can adjust our modeling or investment strategy to reduce the effects of this discrimination while maintaining a high profit.
Analyzing group-level fairness in the LendingClub process
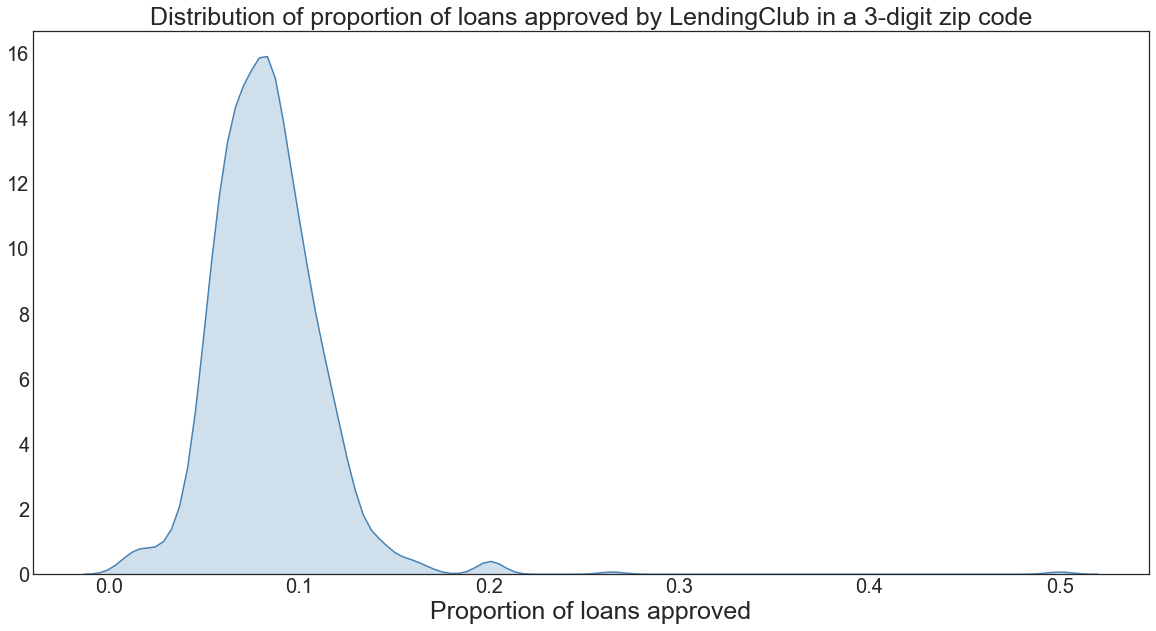
First, let’s take a quick look at the breakdown of Lending Club’s loan approval process. It seems that they approve a small fraction of loans from any given zip code with a fairly normal distribution around the center. This should adjust our expectations for future results - even seemingly small changes in loan approval rates by zip code may translate into meaningful real world changes given this scale.
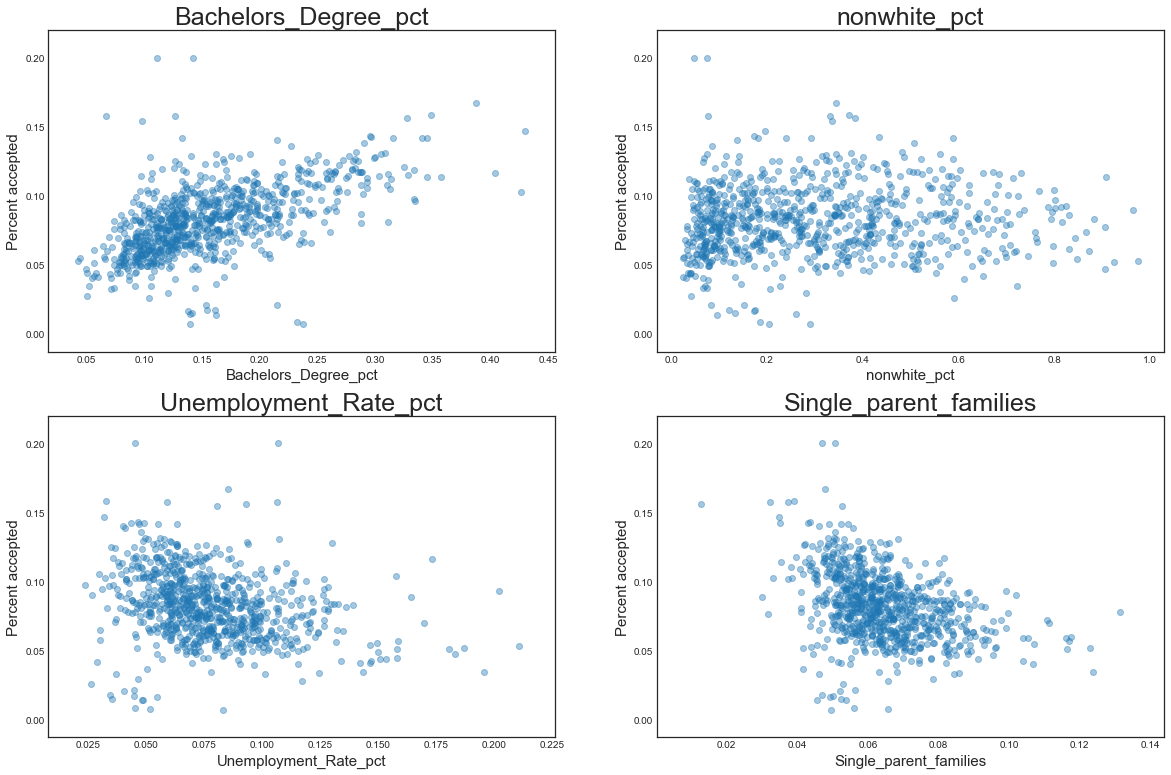
Next we take a look at the relationship between different demographic characteristics and loan approval rates by zip code. It looks like there is a pretty clear trend for education - more highly educated areas have higher loan approval rates. There are slighlty negative correlations for unemployment rate and single parent family composition and there is no discernible trend for race. This should give us another set of expectations for the analysis to come.
Assessing discrimination in our investment strategy
We now turn to our modeling efforts from before. It is important to note that our models have already made attempts at limiting discrimination by careful feature selection and oversampling defaulted loans to allow our model to be more sensitive to these important observations since a natural class imbalance exists in the raw data.
For the following analysis, we consider the loans we would recommend investing in using our ranked ROI from our logistic regression model. This model is among our top performers (as shown in the strategy curves previously shown), but, more importantly, using its predictions serve as an illustrative example since it still allows us to beat the market while still demonstrating discriminatory behavior that our investors may wish to consider in their portfolios.
Here we estimate two ordinary least squares models to make inferences about the relationship between different demographic characteristics and the Lending Club process as well as our own investment strategy.
(1)
(2)
Thus each $\hat{\beta}$ represents the relationship between the demographic composition of a region and (1) the percent of loans that are approved by Lending Club in that region or (2) the percent of loans that we recommend investing in within that region under our investment strategy.
We can interpret the resulting coefficient estimates in (1) to be measures of differential group-level treatment in Lending Club’s loan approval process while the coefficient estimates for model (2) can be viewed as measures of differential group-level treatment in our investment strategy.
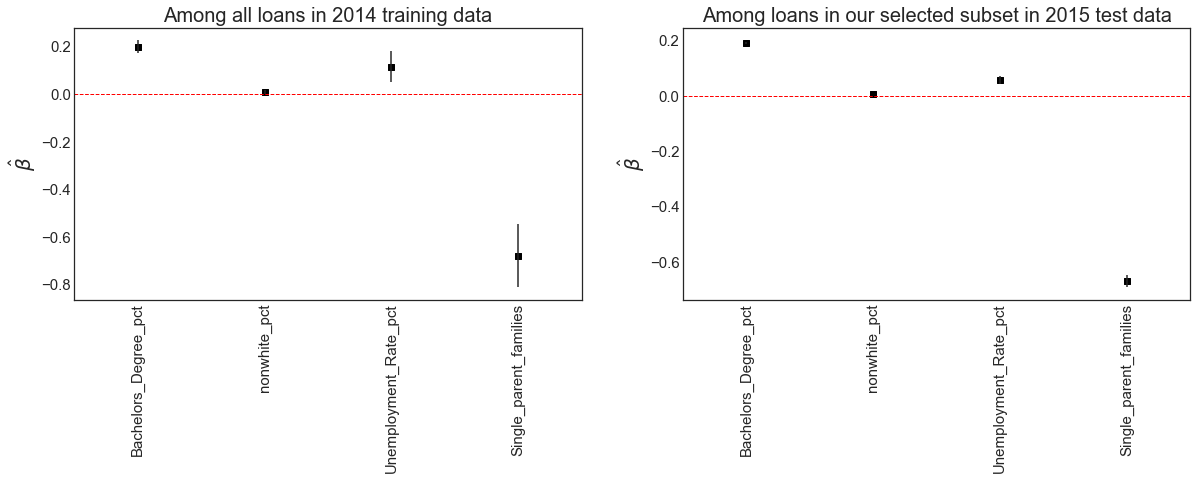
The coefficient plots below, which show the estimate and the 95% confidence interval, are suggestive of a couple of things.
In the Lending Club loan approval process:
- loans are approved at a higher rate in areas with higher levels of education and also higher unemployment rates
- loans are approved at lower rates in areas with fewer single parent families
- racial demographics do not play a meaningful role in a region’s loan approval rate
In our investment strategy:
- loans wind up in our investment portfolio at a higher rate in areas with higher unemployment rates and at a lower rate in areas with fewer single parent families
- education does not play a meaningful role in whether or not we suggest investing in a loan while race plays a mrginally more meaningful role, with loans from more nonwhite areas ending up in our suggested portfolio at a slightly higher rate
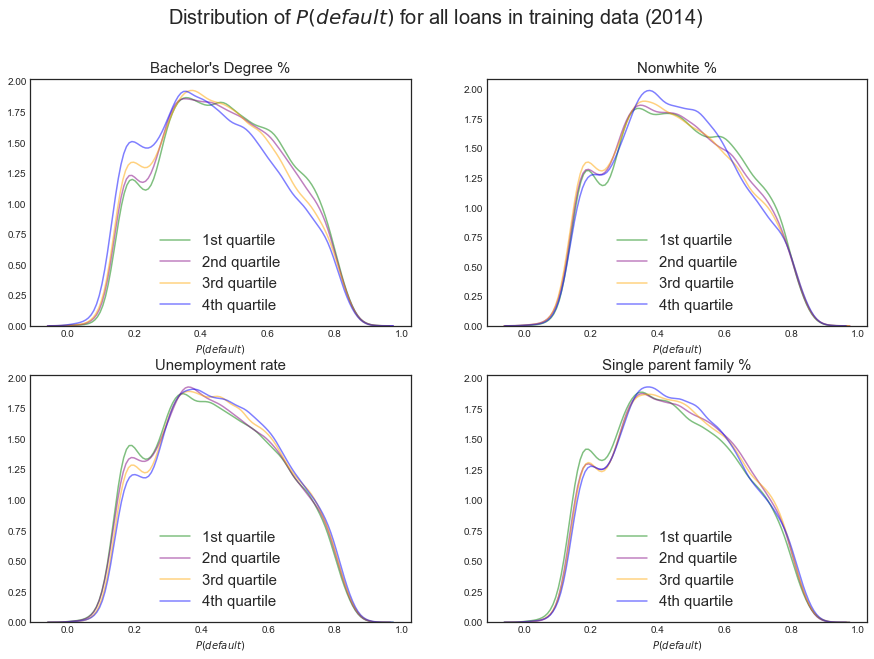
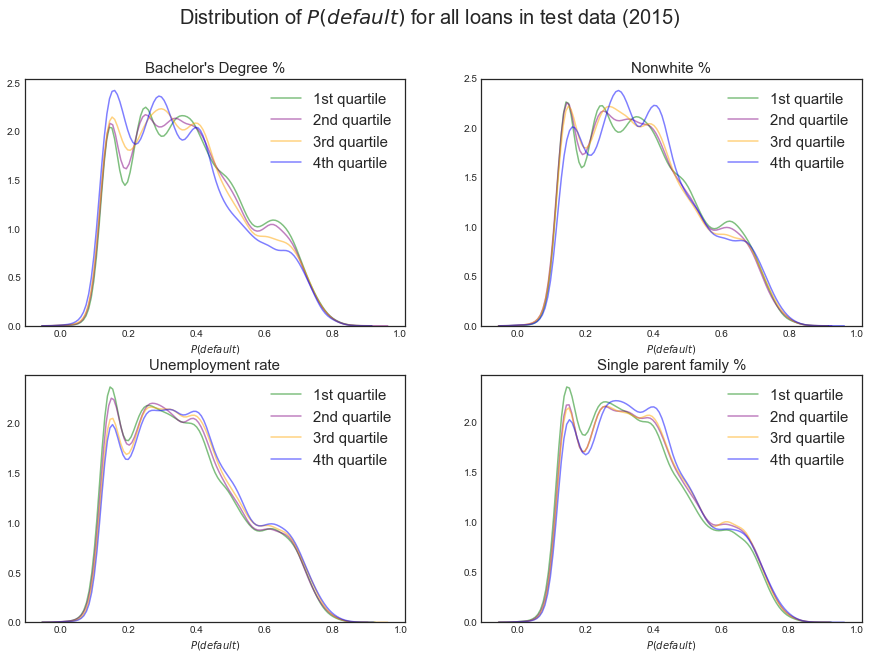
Since the Census demographic data is continuous, it is difficult to label a protected class and a non-protected class to examine discriminatory behavior. We take a novel approach to discretize the characteristics of a loan applicant’s geographic region on these dimensions that we have highlighted as relevant. We split each demographic group into quartiles: the first quartile captures zip codes with the highest concentration of the demographic and the fourth quartile captures zip codes with the lowest concentration of the demographic.
We might find, for instance, that our modeling assigns lower default probability scores and suggests investing more money to the most educated areas while it assigns lower default probabilty scores and suggests investing less money in the least educated areas. We believe this is a fair way of examining discrimination and will easily allow us to remedy discrimination in our initial modeling and strategy.
Overall, we do not find that our model assigns different default probability scores to zip codes with different demographics, as shown in the kernel density estimates for our scores for the four quartiles on the four relevant demographic groups in both the training and test data. The one exception is education. It appears that the highest education bracket is assigned slightly lower default probability scores in both the training and test data. With this caveat, this is promising - perhaps our model with manual feature selection and oversampling is enough to reduce discrimination!
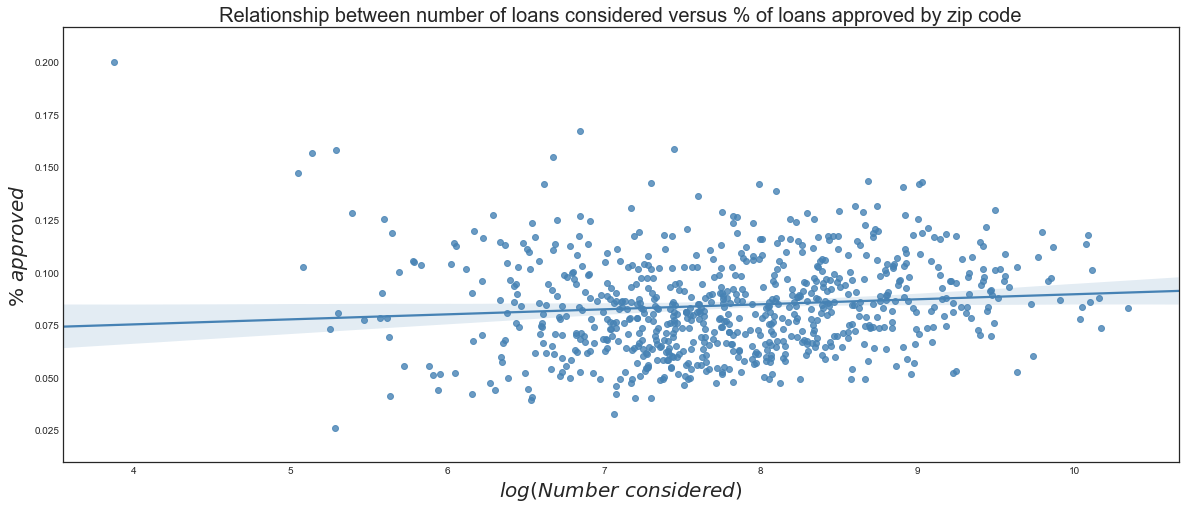
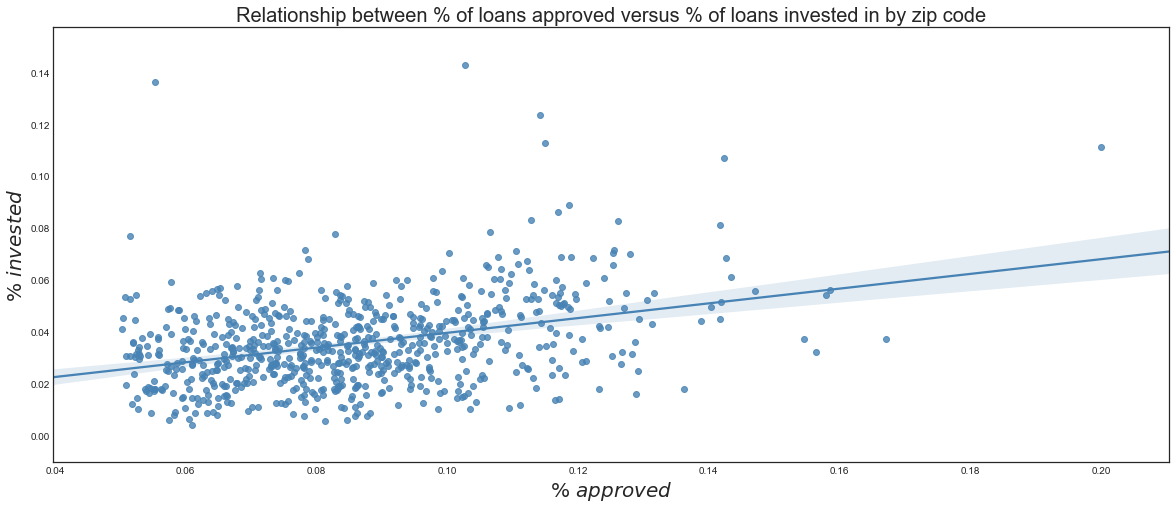
Contrary evidence is presented in the two plots below. In the first plot, we fit a simple linear regression relating the number of loan applications Lending Club receives versus the percent of applications it approves in each zip code. The second plot does the same thing for the relationship between the percent of loans Lending Club approves versus the percent of loans we recommend investing in for each zip code.
We see that Lending Club tends to approve slightly more loans in areas that submit more applications, although the trend is barely noticeable. On the other hand, there is a more discernible relationship between the rate at which Lending Club approves loans by zip code and the rate at which we recommend investing in loans by zip code. This is suggestive of our strategy introducing differential treatment that was not present in Lending Club’s loan approval process. Now, it appears our investment strategy would recommend investing in loans from areas that had high loan approval rates. This has the potential to be problematic: if we direct our investing in areas that are already highly represented in the loan pool, are we simply contributing to a self-fulfilling prophecy?
Note that the loans that we would recommend investing in are determined by considering the case where an investor is looking to invest 200 million dollars into Lending Club loans and taking the subset of our top ranked loans that add up to 200 million dollars. This is less than a half of one percent of Lending Club’s 5.1 billion dollars in loans they granted in 2015.
Adjusting for statistical parity
The story gets more clear once we examine a more relevant features of our investment strategy: how much money we actually suggest investing in zip codes with different demographics makeups. This is easier to understand once we use a case study.
Keeping with the precedence from above, let’s say you are an investor in 2015 looking to invest in 200 million dollars in Lending Club loans. This is a hefty chunk of cash and you are worried that naively lending your money to maximize your profit will lead to you withholding money from groups that are systematically disadvantaged. Conveniently for us, you care about education, unemployment, race, and family status. You’d rather take a small hit in your return if you can invest your money evenly across people with demographic backgrounds.
With this in mind, we can use our current work to produce a statistical parity adjustment for your investment strategy.
Statistical parity means that an equal proportion of defendants are detained in each race group… For example, white and black defendants are detained at equal rates. Formally, statistical parity means, $E[d(X)|g(X)]=E[d(X)]$ (where $d(x)$ is the probability that the positive outcome is assigned to an individual with attributes $x$ while $g(x)$ indicates an individual’s group membership) (Corbett-Davies et al., 2017).
The results we find are quite encouraging. Compared to the baseline investment strategy, which produces a return on investment of 4.92%, we find that performing a statistical parity adjustment on any of these four demographic characteristics produces a return on investment that is only slightly lower than the optimal strategy while significantly balancing the amount of money we funnel into any demographic quartile.
The tables below show the amount of money our initial strategy recommends investing into each bracket of each demographic group, the amount of money our adjusted strategy recommends investing, and the return on investment for that bracket after the adjustment. At the bottom of the table is the overall adjusted return on investment for that demographic parity adjustment.
Before the adjustment, we invest 20 million more dollars into the highest educated areas than we do into the lowest educated areas. Similarly, we invest 16 million more dollars into the areas with the lowest levels of unemployment than we do into the areas with the highest unemployment and nearly 17 million more dollars into areas with the fewest proportion of single parent families as compared to the areas with the largest proportion of single parent families.
These findings are, frankly, astounding.
But with our adjustment we can ensure that we invest the same amount of money into each bracket, as shown by the second column of each table. Notably, our return on investment does not change too much, dipping to 4.77% in the education case. Once we consider the initial 200 million dollar investment, this translates to a difference of just 30,000 dollars.
Considering this essentially negligible tradeoff, we would be happy to offer this socially conscious investing option to an investor.
Recall how our initial investment strategy performed
====================================================
Return on investment if we took all 2015 loans: 0.0325
Return on investment if we took our recommend subset of loans: 0.0492
Bachelors_Degree_pct
========================
| Amount invested before adjustment | Amount invested after adjustment | Return after adjustment | |
|---|---|---|---|
| 1st quartile | 40743175.000 | 49982875.000 | 0.040 |
| 2nd quartile | 47339075.000 | 49997575.000 | 0.047 |
| 3rd quartile | 49610475.000 | 49995800.000 | 0.051 |
| 4th quartile | 62248500.000 | 49998625.000 | 0.054 |
Return on investment after statistical parity adjustment for Bachelors_Degree_pct: 0.0477
nonwhite_pct
========================
| Amount invested before adjustment | Amount invested after adjustment | Return after adjustment | |
|---|---|---|---|
| 1st quartile | 45160700.000 | 49991500.000 | 0.047 |
| 2nd quartile | 54032575.000 | 49974225.000 | 0.048 |
| 3rd quartile | 53842550.000 | 49985750.000 | 0.049 |
| 4th quartile | 46905400.000 | 49995725.000 | 0.052 |
Return on investment after statistical parity adjustment for nonwhite_pct: 0.0491
Unemployment_Rate_pct
========================
| Amount invested before adjustment | Amount invested after adjustment | Return after adjustment | |
|---|---|---|---|
| 1st quartile | 58075850.000 | 49980400.000 | 0.053 |
| 2nd quartile | 53872850.000 | 49991750.000 | 0.049 |
| 3rd quartile | 46060475.000 | 49991325.000 | 0.047 |
| 4th quartile | 41932050.000 | 49972650.000 | 0.045 |
Return on investment after statistical parity adjustment for Unemployment_Rate_pct: 0.0487
Single_parent_families
========================
| Amount invested before adjustment | Amount invested after adjustment | Return after adjustment | |
|---|---|---|---|
| 1st quartile | 59937700.000 | 49988950.000 | 0.055 |
| 2nd quartile | 49879150.000 | 49998350.000 | 0.048 |
| 3rd quartile | 47129325.000 | 49965975.000 | 0.048 |
| 4th quartile | 42995050.000 | 49989500.000 | 0.043 |
Return on investment after statistical parity adjustment for Single_parent_families: 0.0483
Other approaches
Other similar adjustments could be made for conditional parity (statistical parity conditional on some legitimate risk factor) or predictive equality (equal false positive rates across groups) (Corbett-Davies et al., 2017).
Another useful approach might be to employ a tool like a local surrogate model (such as LIME) to investigate the behavior of our model around the decision boundary and get a sense of what features play a role in assigning an observation to the positive or negative outcome (Ribeiro, M.T., Singh, S. and Guestrin, C., 2016). We could also do this through a tool like Quantitative Input Influence (QII), which uses causal inference techniques to examine the marginal influence of features on predictions (Datta et al, IEEE S&P 2016).
Instead of making post-modeling adjustments, we could also bake a notion of group-level equity into our model’s loss function. This can be done through packages such as themis-ml or IBM’s AIF360, which capture a host of methods used for bias mitigation at the time of model building.
We do not claim that statistical parity is the best approach to use in this case. We acknowledge that focusing on this one notion of fairness can lead to unintended discrimination at the individual level (Dwork et al., 2011). We hoped to implement a model from either themis-ml or AIF360 but simply ran out of time.
We do argue that our approach of manually addressing discrimination rather than allowing another algorithm to address it left us with a full understanding of what this type of adjustment looks like and what kind of tradeoffs exist between fairness and maximizing an objective (here, return on investment). We are satisified with the complexity and encouraged that fairness constraints can be implemented in Lending Club more thoroughly without hurting investors incentive’s.